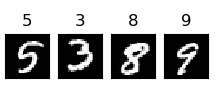
Pythonの深層学習モジュール「Keras」で手書き文字認識(mnist)の学習・識別方法をソースコード付きで解説します。
【Keras】mnistの手書き文字認識
mnist(エムニスト)のデータセットは、「6万枚の手書き数字の学習用画像」と「1万枚のテスト画像」が格納されています。
これらの画像は全て28×28[px]のグレースケール画像となっています。
mnistのデータセットは、機械学習の性能評価によく用いられます。
MNISTの手書き数字画像
| – | – |
|---|---|
| 入力データ | 1つの数字が書かれた画像データ。MNISTの画像1つは 28×28(=784)pxの大きさです。 1pxに「白:255」〜「黒:0」までの色情報が記録されています。 1つの画像の全てのピクセルの情報を入力するので、入力数は784個となる。 |
| 出力データ | 入力された画像データが「0」〜「9」のどの数字画像なのか、その確率を「0」〜「9」毎に出力。そのため出力数は10で、最も確率の高いものが、予測結果の数字となる。
例「0.7, 0, 0, 0, 0, 0, 0.2, 0, 0, 0.1」 |
| One-Hotエンコーディング | One-Hotとは、「1つだけ1でそれ以外は0のベクトル(行列)」のことです。One-Hotエンコーディングは、カテゴリー変数をOne-Hotのベクトル(行列)に変換することです。 |
【サンプルコード1】データセットを使って分類器を作成
サンプルプログラムのソースコードです。
【サンプルコード2】作成した分類器で手書き画像の分類
作成した分類器をロードし、以下の「2」と描かれた画像を入力して、数字を当てられるか試してみます。
画像のロード、変換等はOpenCVを使います。

無事に「2」と正解できました。

【TensorFlow版Keras入門】ディープラーニングを簡単に学ぶ方法
Pythonモジュール「TensorFlow/Keras」で深層学習(ディープラーニング)を行う方法について入門者向けに使い方を解説します。
python.joho.info
2024.06.30

コメント