Pythonと機械学習ライブラリ「scikit-learn」によるニューラルネットワーク(多層パーセプトロン・MLP)の使い方についてまとめました。
【はじめに】ニューラルネットワークとは
ニューラルネットワーク (Neural network)とは、人の脳内にある神経回路を参考にした学習モデルです。
多層パーセプトロン(MLP)とは、パーセプトロンを複数繋いで多層構造にしたニューラルネットワークです。

機械学習ライブラリ「Scikit-learn」では、バージョン0.18.0からニューラルネットワーク(NN)を利用できるようになりました。
今回は、それを用いてCSVファイルのデータを読み込んで学習させてみます。
書式
scikit-learnでは、sklearn.neural_network.MLPClassifierクラスを使うことでニューラルネットワーク(NN)を実装できます。
このクラスは、ニューラルネットワークでよく利用されている多層パーセプトロン(MLP)方式です。
sklearn.neural_network.MLPClassifier(hidden_layer_sizes=(100, ), activation='relu', solver='adam', alpha=0.0001, batch_size='auto', learning_rate='constant', learning_rate_init=0.001, power_t=0.5, max_iter=200, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
※各パラメータに設定されてる値(=の後)はデフォルト値
| パラメータ(引数) | 内容 |
|---|---|
| hidden_layer_sizes=(100, ) | 隠れ層のノード数(多層化可能) |
| activation=’relu’ | 活性化関数(identify, logistic, tanh, relu) |
| solver=’adam’ | 最適化手法(lbfgs, sgd, adam) |
| alpha | L2ペナルティ(正則化の項) |
| batch_size=’auto’ | 最適化のバッチサイズ(sgd、adam用) |
| learning_rate | 重み更新のための学習率スケジュール(’定数’、 ‘invscaling’、 ‘adaptive’) |
| max_iter=200 | 反復の最大回数 |
| shuffle | 反復する度にサンプルをシャッフルするか(solverが’sgd’か’adam’の時に使用) |
| random_state | 乱数生成の状態 or シード(int、RandomState) |
| tol | 最適化の許容誤差 |
| power_t | スケーリング学習率の指数 |
| verbose | 進捗メッセージを標準出力するかどうか |
| warm_start | 以前の呼び出しの解を再利用して初期化するかどうか |
| momentum | 勾配降下更新のモメンタム |
| nesterovs_momentum | 訓練データの10%が妥当性検査として自動設定され、2つの連続したエポックで少なくとも妥当性スコアが改善していない場合は訓練終了(solver = ‘sgd’または ‘adam’で有効) |
| early_stopping | 検証スコアが改善されていないとき訓練中止のために早期停止を使用するかどうか |
| validation_fractionv | 早期停止のための妥当性確認として設定される訓練データの割合 |
| beta_1 | adamの第1モーメントベクトルの推定値に対する指数関数的減衰率 |
| beta_2 | adamの第2モーメントベクトルの推定値に対する指数関数的減衰率 |
| epsilon | adamの数値安定性の値(solver = ‘adam’で使用) |
ソースコード
サンプルプログラムのソースコードです。
表示されない場合は、「https://github.com/nishizumi-lab/sample/blob/master/python/scikit/mlp/ex2.py」をご覧ください。
学習用データ
テスト用データ
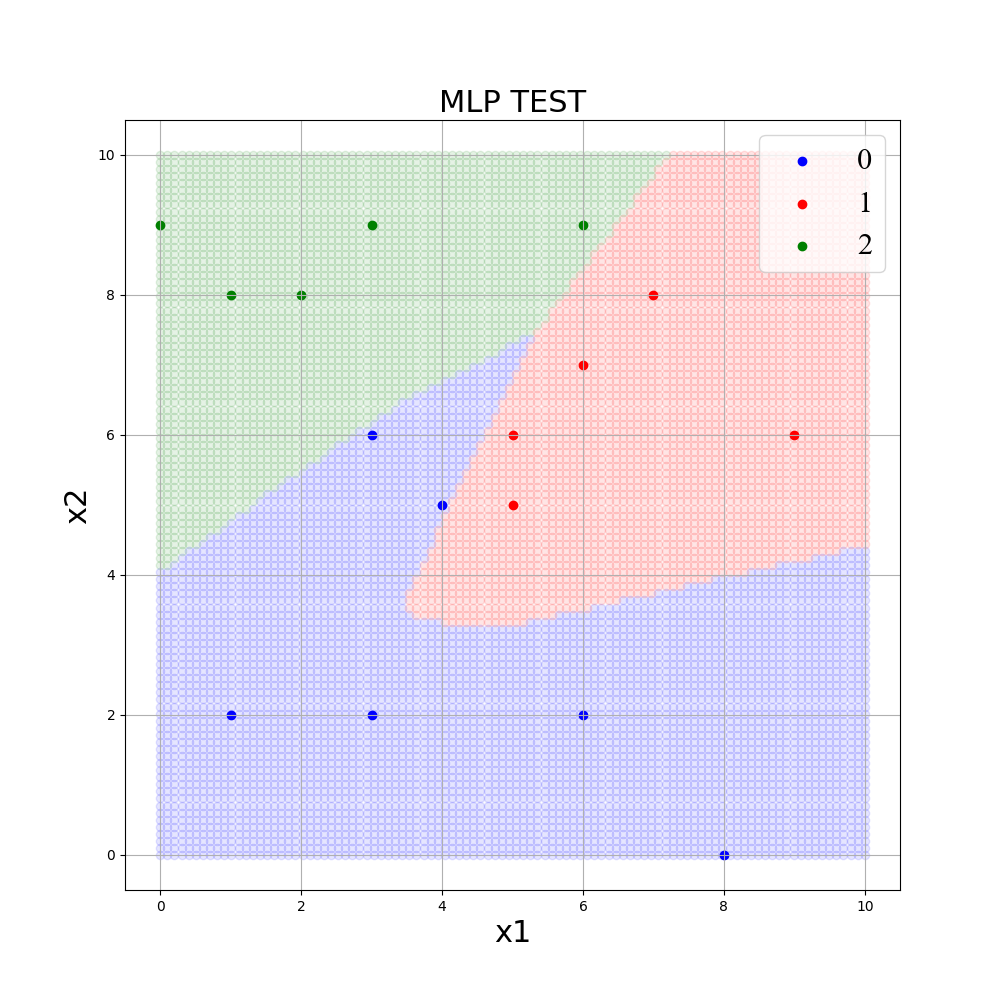
MLPの決定境界を可視化
前回記事では、Pythonと機械学習ライブラリ「scikit-learn」でニューラルネットワーク(多層パーセプトロン・MLP)の学習モデルを作成しました。

今回は、Scikit-learnで作成した学習済みモデルをグラフで可視化(生成された決定境界を描画)します。
やり方は簡単で、説明変数に合わせた細かい入力データを作り、学習したモデルで分類を行い塗りつぶしていきます。
その際、各クラスを色分けしてプロットすることで、決定境界(分類の境界線)が浮かび上がります。
細かいデータを作る際は、numpyのmeshgridを使うと便利です。
ソースコード
サンプルプログラムのソースコードです。
学習用データ
テスト用データ

コメント