
Pythonライブラリ「Scikit-learn」で生成した学習済みモデルの訓練データに対する適合性を評価する方法をサンプルコード付きで解説します。
訓練データに対する適合性評価
訓練データに対する適合性評価は、学習済みモデルが訓練用データにどれだけ合っているかを決定係数 $ R^2 $などの指標で評価することです。ただし、スコアが高すぎると、過学習の可能性もあるので注意が必要です。
決定係数 $ R^2 $ は、回帰直線が実測値(訓練用データなど)にどれだけうまく沿っているかを示す指標です。決定係数$ R^2 $は 0〜1の範囲の値をとります。値が1に近いほど、実測値に近いと評価できます。
- $ R^2 = 1 $:すべての実測値が回帰直線上にあり、完全に再現できている。(理想的なモデル)
- $ R^2 \approx 0.8 $:実測値が回帰直線の付近にあり、高い予測精度がある。(実用的なモデル)
- $ R^2 = 0 $:実測値が回帰直線から大きく外れており、予測精度が低い。(不適なモデル)
決定係数の計算方法など、数理的な内容は以下ページで解説しています。
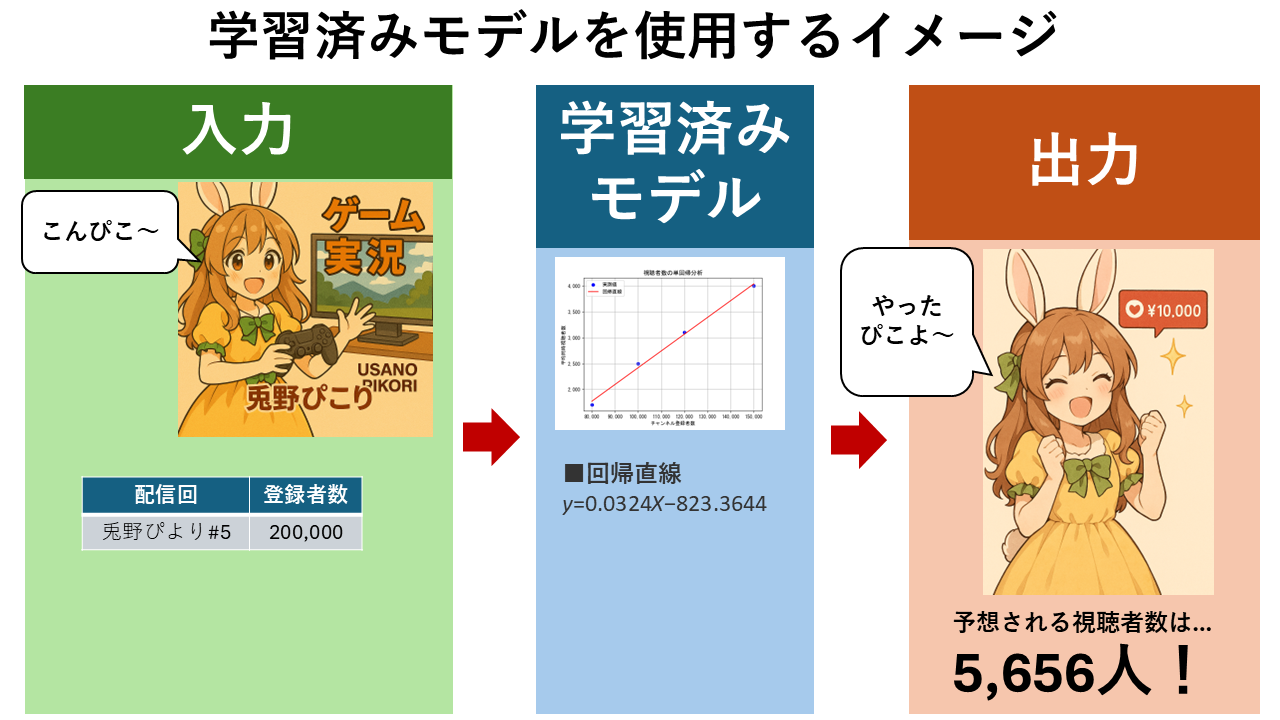
【単回帰分析とは】計算式の仕組みをVTuberの視聴者数予測を例にわかりやすく解説
単回帰分析とは?計算式の仕組みや求め方、決定係数による性能検証方法などをVTuberの視聴者数予測を例をわかりやすく解説します。
algorithm.joho.info
サンプルコード① 単回帰分析の場合
単回帰モデルの決定係数を求めるサンプルコードが以下になります。
※読み込んだデータ:dataset01.csv
コード解説
重要な箇所に絞って解説します。
from sklearn.metrics import r2_score
scikit-learnのmetricsモジュールには、モデルの性能を評価する関数が多数あります。r2_scoreはその中の1つで、回帰モデルの決定係数(R²)を計算する関数です。
r2_train = r2_score(y_train, y_train_pred)
r2_score()は、実際の値y_trainと予測値y_train_predの一致度を評価し、訓練データに対する決定係数 R² が得られます。
print("訓練データに対する R²(決定係数):", r2_train)
- R²を表示。1.0に近いほど「訓練データに対してよく当てはまっている」
関連ページ
以下ページでは、Pythonライブラリ「scikit-learn」の使い方を数理的な背景も含めて解説していますので、是非ご一読ください。

【Scikit-learn超入門】使い方をサンプルコード付きで解説
Pythonライブラリ「Scikit-learn」で機械学習を行う方法を入門者向けに解説します。
python.joho.info
2024.06.30

コメント