
Pythonライブラリ「scikit-learn」で生成した学習済みモデルをファイルに保存したり、読み込んで使用する方法をサンプルコード付きで解説します。
学習済みモデルのファイル保存&読み込み
① 以下は、単回帰の学習済みモデルを「sample02-1.learn」ファイルに保存するプログラムです。
② 以下は、「sample02-1.learn」ファイルを読み込み、学習済みモデルを使ってチャンネル登録者数20万人のときの視聴者数を予測するプログラムです。
コード解説
import joblib
joblibは、モデルを保存・読み込みするためのライブラリです。
joblib.dump(model, "C:/github/sample/python/scikit-learn/tutorial/LinearRegression/single/sample02-1.learn")
.learnという拡張子は任意ですが、ここでは学習済みモデルを保存しています。後でjoblib.load()で読み込めば、再学習せずに予測に使えます。
関連ページ
機械学習の仕組みについては、以下ページで解説しています。
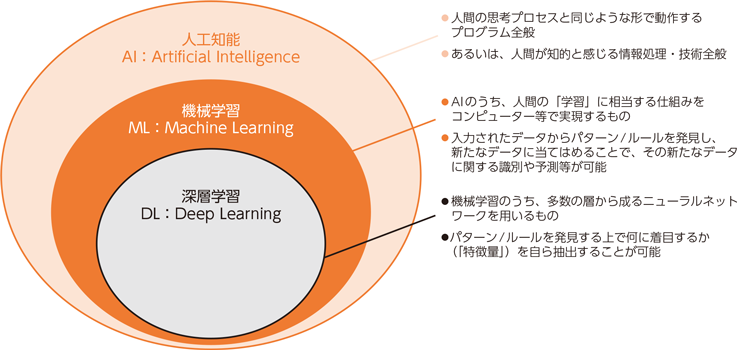
【機械学習のアルゴリズム超入門】原理からプログラミング実装例まで解説
機械学習のアルゴリズム(原理)やプログラミング方法について入門者向けにまとめました。
algorithm.joho.info
Pythonライブラリ「Scikit-learn」を用いた機械学習の実装方法については、以下ページで解説しています。

【Scikit-learn超入門】使い方をサンプルコード付きで解説
Pythonライブラリ「Scikit-learn」で機械学習を行う方法を入門者向けに解説します。
python.joho.info
2024.06.30

コメント