Pythonと機械学習ライブラリ「scikit-learn」を用いて、サポートベクタマシン(SVM)による教師あり学習を行う方法について紹介します。
【1】サポートベクターマシンで2クラス分類
サポートベクターマシン(略称:SVM)は、教師あり学習モデルの1つです。
2クラスのパターン識別器としては非常に強力なモデルで、データの分類や回帰などで大きな効果を発揮しています。
【特徴】予測対象:分類, 学習タイプ:教師あり, 可読性:○, 並列処理:✕
マージン最大化のアイデアにより、汎化性能が高い2分類を行います。計算コストは高めです。

書式
Scikit-learnでは、「svm.SVC()」を用いることでサポート・ベクター・マシン(SVM)を実装できます。
svm.SVC(gamma, C)
| パラメータ | 説明 |
|---|---|
| gamma | rbf, poly, sigmoidカーネル(ガウシアンカーネル)のパラメータです。(値が大きいほど境界が複雑になる) |
| C | どれだけ誤分類を許容するかのパラメータです。(値が小さいほど誤分類を許容) |
| kernel | 非線形の境界線を生成するのに必要なパラメータ。カーネル関数の種類(デフォルトはrbf)。rbf(RBFカーネル), linear(線形カーネル:これを使うと単純な線形となるが処理速度は速い), poly(多項式カーネル), sigmoid(シグモイドカーネル)などを指定できる。 |
ソースコード
サンプルプログラムのソースコードです。
検証結果をみると、「x1とx2の和が10以上・・・x3は1、x1とx2の和が10未満・・・x3は0」と判別していることがわかります。
学習用データ(train.csv)
x1とx2の和が10以上・・・x3は1
x1とx2の和が10未満・・・x3は0
テスト用データ(test.csv)

【2】決定境界を描画して、学習済みモデルの可視化
Scikit-learnで作成した学習済みモデルをグラフで可視化(生成された決定境界を描画)します。
やり方は簡単で、説明変数に合わせた細かい入力データを作り、学習したモデルで分類を行い塗りつぶしていきます。
その際、各クラスを色分けしてプロットすることで、決定境界(分類の境界線)が浮かび上がります。
細かいデータを作る際は、numpyのmeshgridを使うと便利です。
動画解説
サンプルコード
ロードする入力データは、前項と同じものです。
実行結果
パラメータを色々変えて実行した結果です。
■gamma = 0.001, C=100., kernel=’linear’

■gamma = 0.001, C=100., kernel=’rbf’
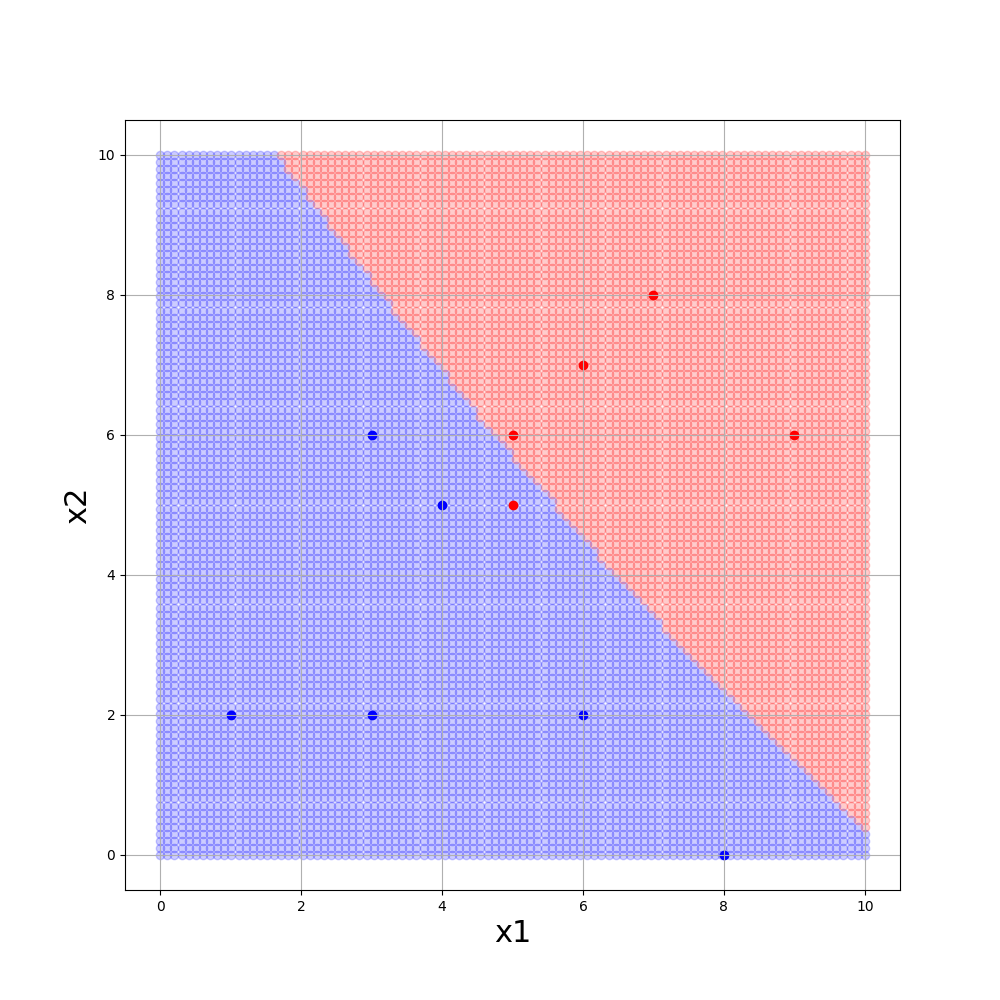
■gamma = 0.01, C=10., kernel=’rbf’
gammmaが大きいほど境界が複雑になり、Cが小さいほど誤分類を許容します。
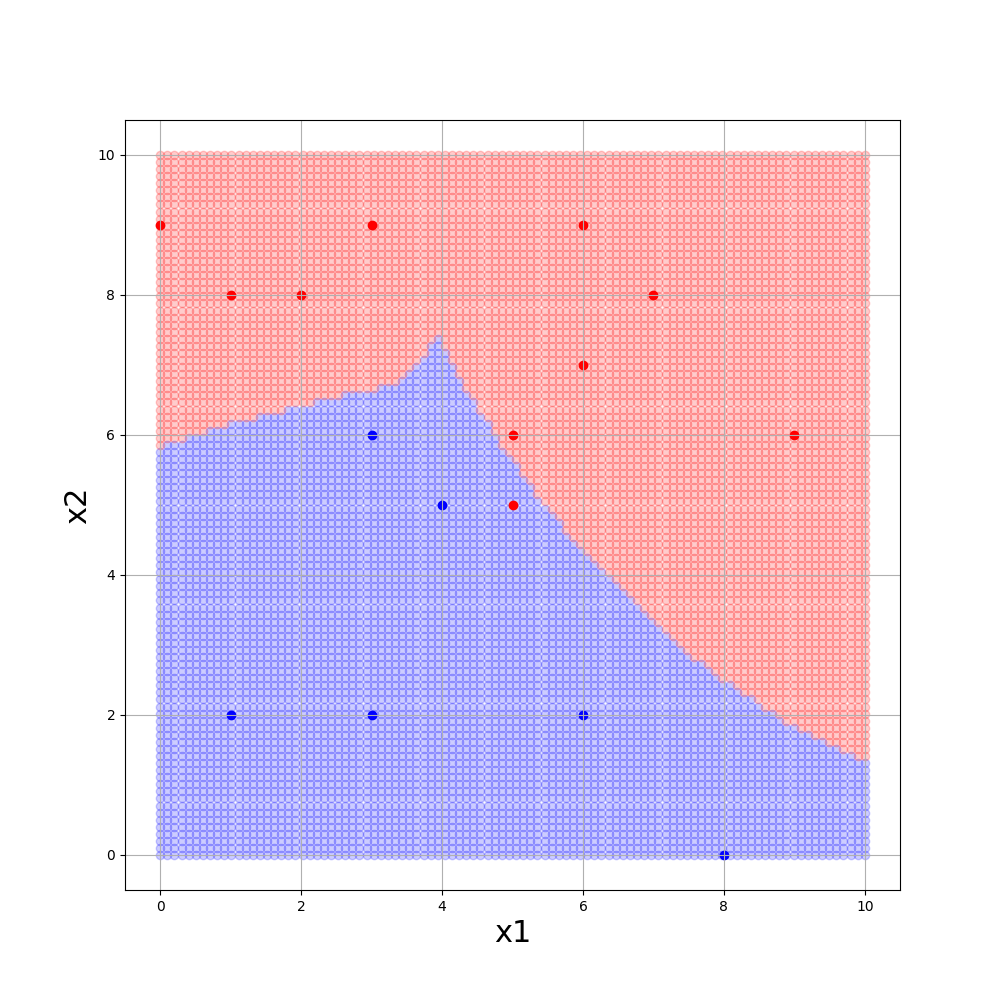
■gamma = 0.1, C=1., kernel=’rbf’
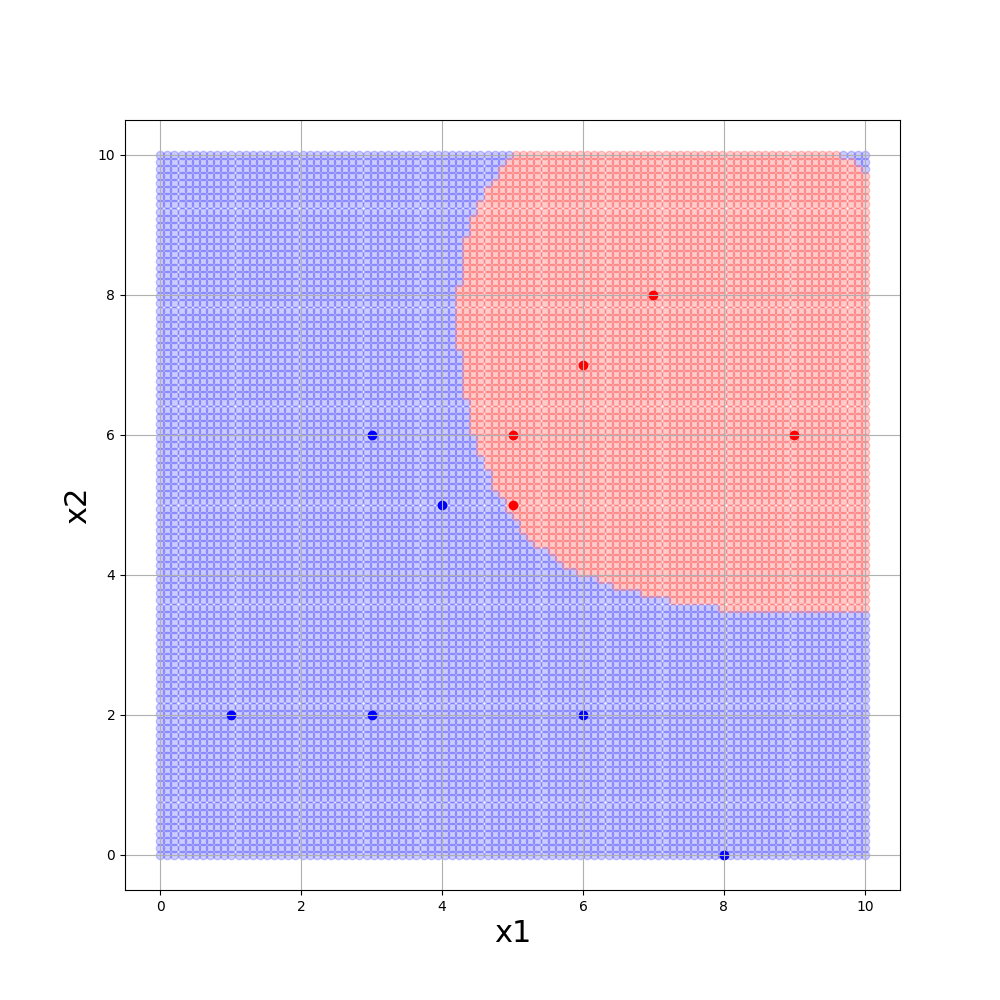
■gamma = 0.1, C=1., kernel=’poly’
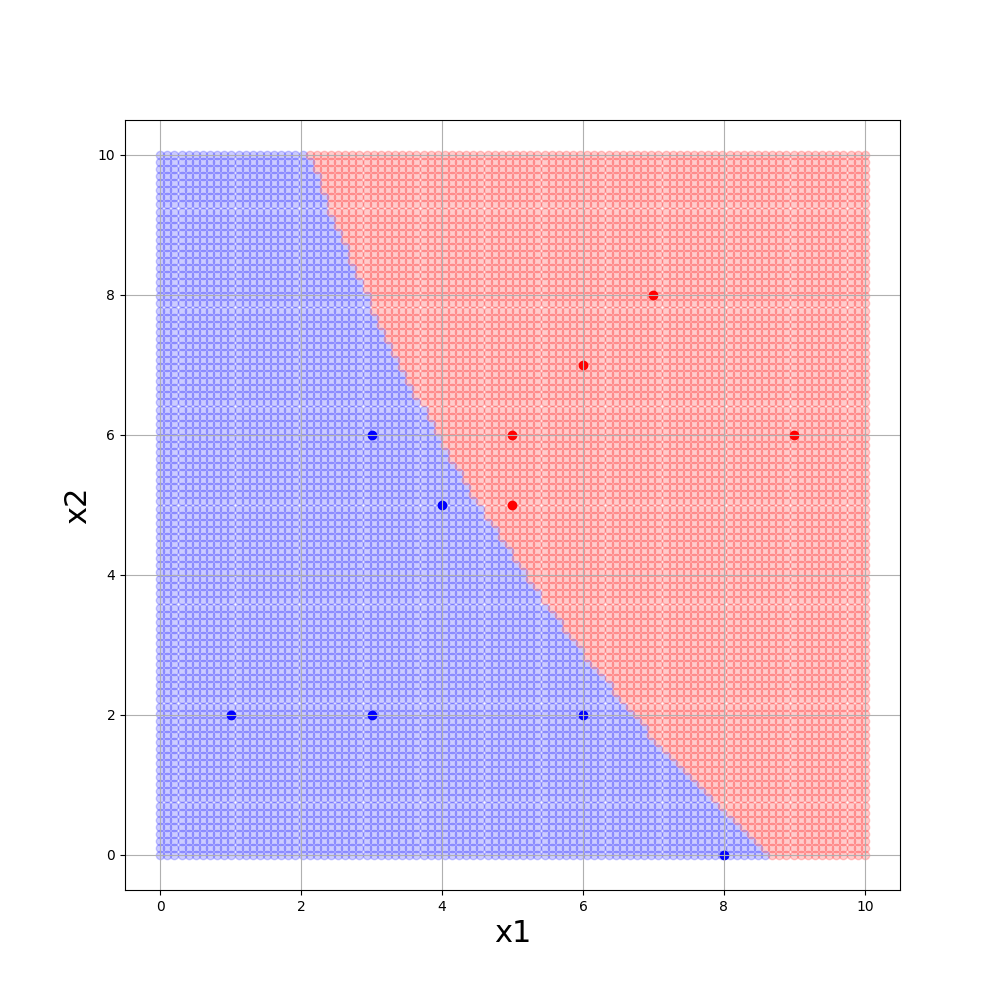
■gamma = 0.1, C=100., kernel=’sigmoid’
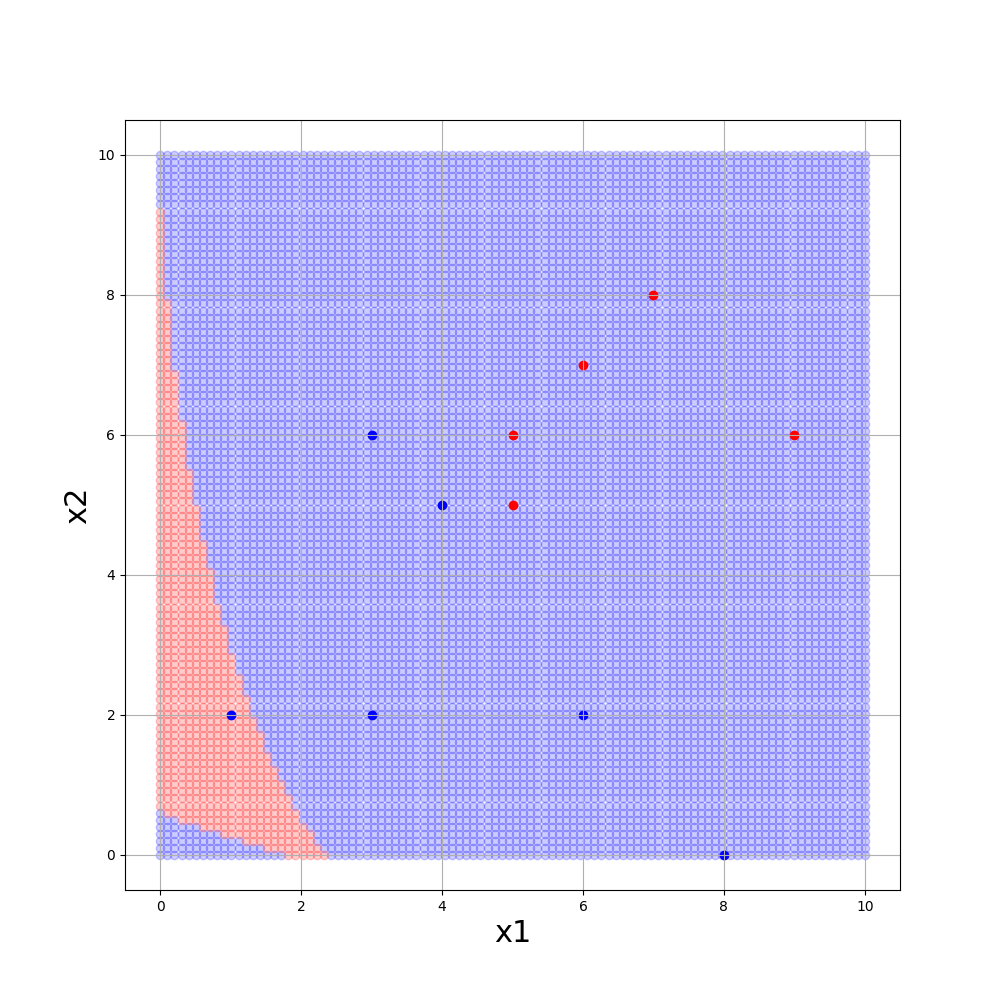
【3】多クラス分類
Scikit-learnのSVMは、多クラス分類も行えます。
方法は、学習用データの目的変数(教師ラベル)をクラス数分増やすだけでコードは2分類と変わりません。
動画解説
本ページの内容は以下動画でも解説しています。
ソースコード
サンプルプログラムのソースコードです。
学習用データ(train.csv)
目的変数(教師ラベル)を0, 1, 2の3種類に増やしています
テスト用データ(test2.csv)
実行結果

【4】拡張しやすいようclass化したコード
前節のソースコードを、クラス数が増えた場合などに拡張しやすいよう修正したコードも掲載します。
動画解説
本ページの内容は以下動画でも解説しています。
【5】アヤメの品種分類(Irisデータセット)
Scikit-learnには、様々なサンプルデータ(学習用のデータセット)が用意されています。
今回はそのうち、Irisデータセットを使ってアヤメの品種分類をSVM(サポートベクターマシン)で行ってみます。
データセットの中身は次のとおり。
| 種別 | 概要 |
|---|---|
| 説明変数 | sepal length(ガクの長さ)、sepal width(ガクの幅)、petal length(花弁の長さ)、petal width(花弁の幅) |
| 目的変数 | アヤメの品種(’setosa’=0 ‘versicolor’=1 ‘virginica’=2) |
| CSV | https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/datasets/data/iris.csv |
動画解説
サンプルコード
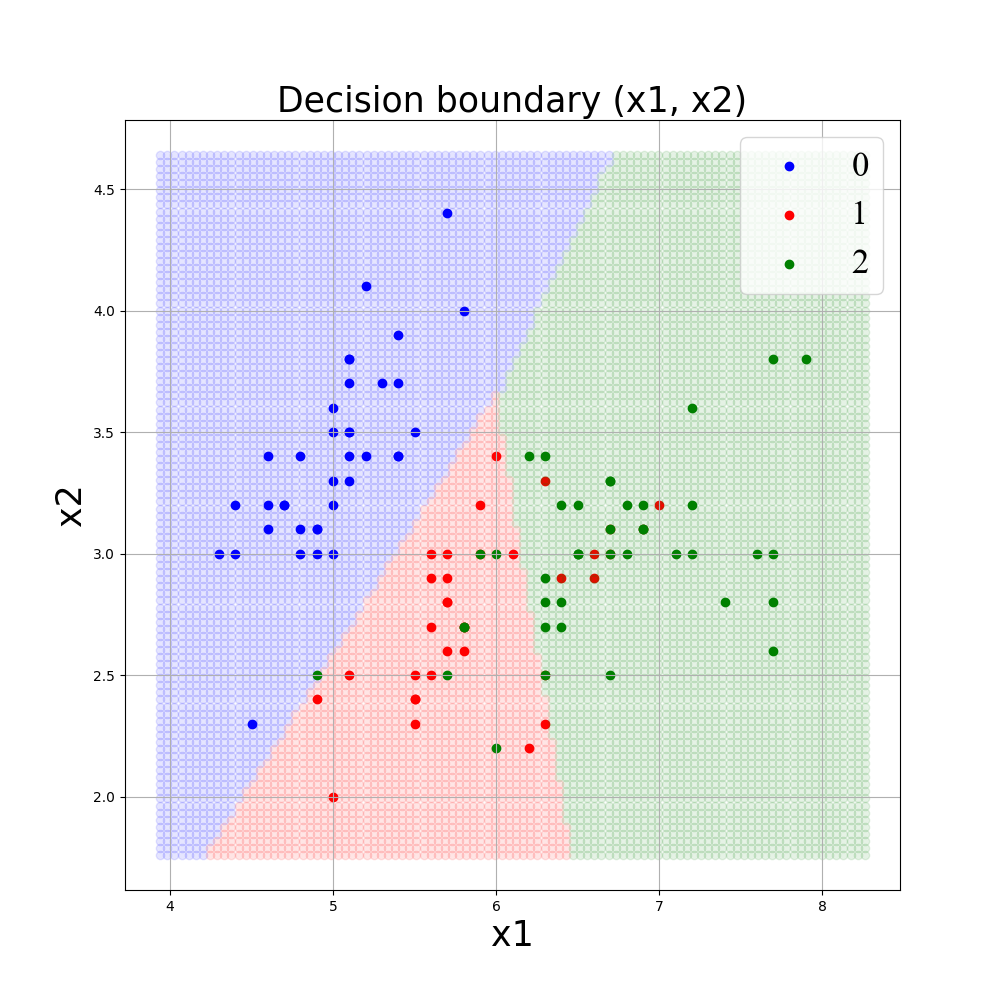
■x1, x2を説明変数としてgamma = 0.1, C=1., kernel=’rbf’でSVMモデルにより学習したときの決定境界
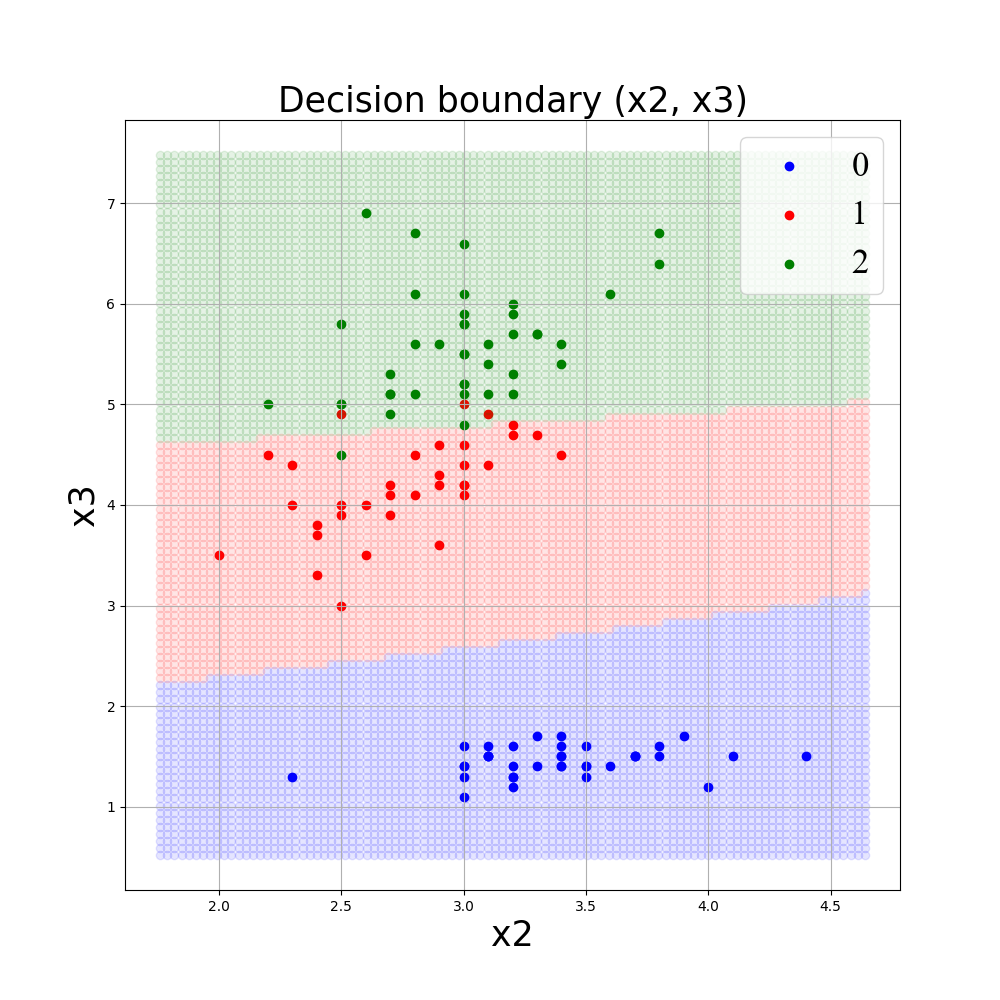
■x2, x3を説明変数としてgamma = 0.1, C=1., kernel=’rbf’でSVMモデルにより学習したときの決定境界
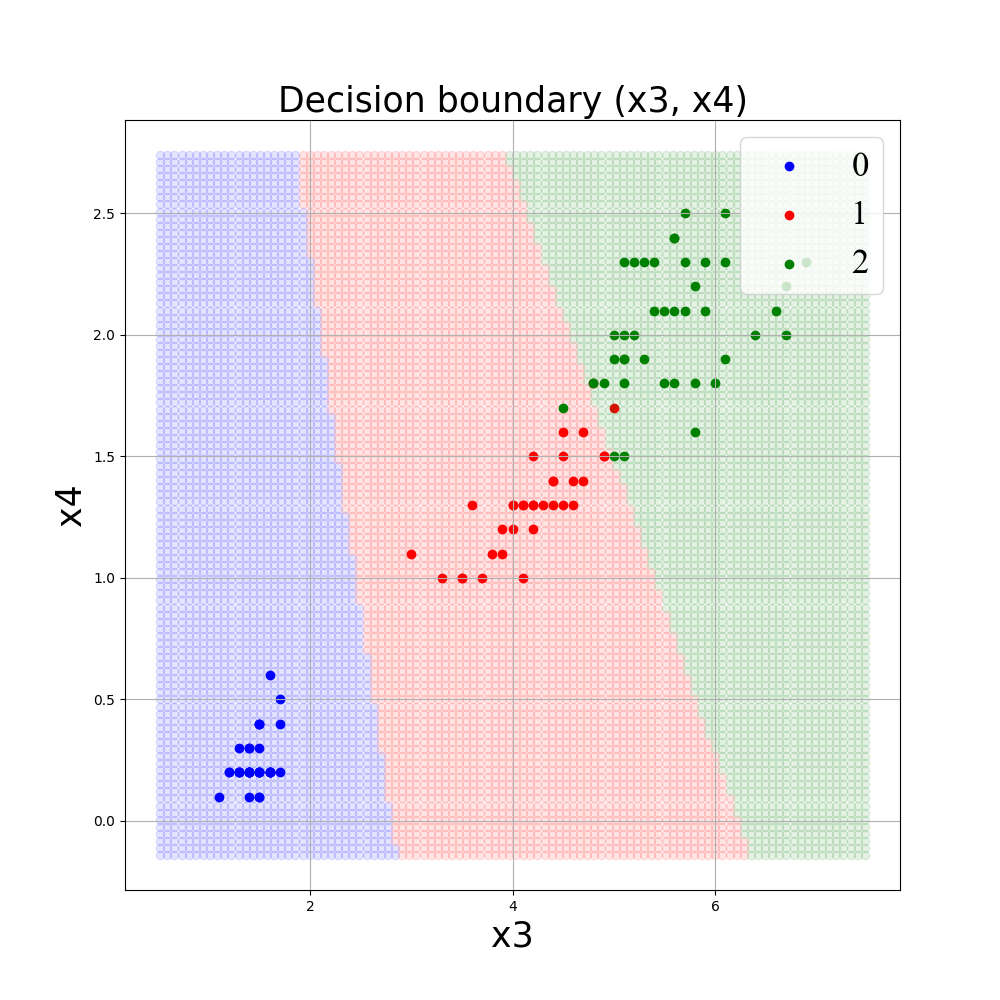
■x3, x4を説明変数としてgamma = 0.1, C=1., kernel=’rbf’でSVMモデルにより学習したときの決定境界
【6】手書き数字画像から数字を判別(digitsデータセット)
Scikit-learnには、様々なサンプルデータ(学習用のデータセット)が用意されています。
今回はそのうち、手書き数字画像(Digits データセット)を使って数字判別をSVM(サポートベクターマシン)で行ってみます。
データセットの中身は次のとおり。
| 種別 | 概要 |
|---|---|
| 説明変数 | 0~9の描き数字が描かれた画像データ群。画像1枚あたり8*8の二次元配列で格納されている。また、画素値は0~16で黒(背景部分)、白(数字部分)となっている。 |
| 目的変数 | 各画像の正解ラベル(0~9) |
| 例 | https://scikit-learn.org/stable/auto_examples/cluster/plot_digits_agglomeration.html#sphx-glr-auto-examples-cluster-plot-digits-agglomeration-py |
動画解説
サンプルコード
以下のテスト画像を入力し、「2」と予測されました。



コメント